Deep neural network functions¶
--> -->Please access the video via one of the following two ways
Motivation: from finite element to neural network¶
In this chapter, we will introduce the so-called shallow neural network (deep neural network with one hidden layer) from the viewpoint of finite element method.
Let us first consider the linear finite element functions on the unit interval \(\bar{\Omega}=\) \([0,1]\) in \(1 \mathrm{D}\). We then consider a set of equidistant girds \(\Omega_{\ell}\) of level \(\ell\) on the unit interval \(\bar{\Omega}=[0,1]\) and mesh length \(h_{\ell}=2^{-\ell}\). The grid points \(x_{\ell, i}\) are given by
For \(\ell=1\), we denote the special hat function:
The next diagram shows this basis function:
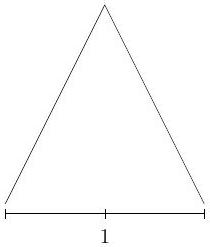
Fig. 13 Diagram of \(\varphi(x)\)¶
Then, for any nodal basis function \(\varphi_{\ell, i}\) as below:
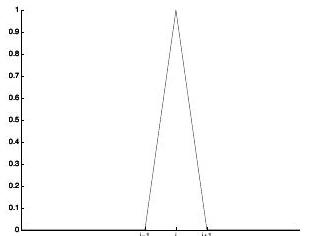
Fig. 14 Diagram of \(\varphi_{\ell, i}(x)\)¶
in a fine grid \(\mathcal{T}_{\ell}\) can be written as
That is to say, any \(\varphi_{\ell, i}(x)\) can be obtained from \(\varphi(x)\) ba scaling (dilation) and translation with
in \(\varphi_{\ell, i}=\varphi\left(w_{\ell} x+b_{\ell, i}\right)\).
Let recall the finite element interpolation as
for any smooth function \(u(x)\) on \((0,1)\). The above interpolation will converge as \(\ell \rightarrow \infty\), which show that
Thus, we may have the next concise relation:
FE space \(=\operatorname{span}\left\{\varphi\left(w_{\ell} x+b_{\ell, i}\right) \mid 0 \leq i \leq 2^{\ell}, \ell=1,2, \cdots\right\} \subset \operatorname{span}\{\varphi(w x+b) \mid w, b \in \mathbb{R}\} .\)
In other words, the finite element space can be understood as the linear combination of \(\varphi(w x+b)\) with certain special choice of \(w\) and \(b\).
Here, we need to point that this \(\operatorname{span}\{\varphi(w x+b) \mid w, b \in \mathbb{R}\}\) is exact the deep neural networks with one hidden layer (shallow neural networks) with activation function \(\varphi(x)\). More precisely,
means there exist positive integer \(N\) and \(w_{j}, b_{j} \in \mathbb{R}\) such that
The above function is also called one hidden neural network function with \(N\) neurons.
Remark
1- By making \(w_{\ell}\) and \(b_{\ell, i}\) arbitrary, we get a much larger class of function which is exact a special neural network with activation function \(\varphi(x)\).
2- Generalizations:
a) \(\varphi\) can be different, such as \(\operatorname{ReLU}(x)=\max \{0, x\}\).
b) There is a natural extension for hight dimension \(d\) as
where \(w \in \mathbb{R}^{d}, b \in \mathbb{R}\) and \(w \cdot x=\sum_{i=1}^{d} w_{i} x_{i}\). This is called “deep” neural network with one hidden layer.
Why we need deep neural networks via composition¶
FEM ans DNN \(_{1}\) in 1D¶
Thanks to the connection between \(\varphi(x)\) and \(\operatorname{ReLU}(x)=\{0, x\}\)
It suffices to show that each basis function \(\varphi_{\ell, i}\) can be represented by a ReLU DNN. We first note that the basis function \(\varphi_{i}\) has the support in \(\left[x_{i-1}, x_{i+1}\right]\) can be easily written as
More generally, if function \(\varphi_{i}\) is not on the uniform grid but has support in \(\left[x_{i-1}, x_{i+1}\right]\) can be easily written as
where \(h_{i}=x_{i+1}-x_{i}\).
Thus is to say, we have the next theorem.
Theorem 7
For \(d=1\), and \(\Omega \subset \mathbb{R}^{d}\) is a bounded interval, then DNN \(_{1}\) can be used to cover all linear finite element function in on \(\Omega\).
Linear finite element cannot be recovered by DNN \(_{1}\) for \(d \geq 2\)¶
In view of Theorem 7 and the fact that \(\mathrm{DNN}_{\mathrm{J}} \subseteq \mathrm{DNN}_{\mathrm{J}+1}\), it is natural to ask that how many layers are needed at least to recover all linear finite element functions in \(\mathbb{R}^{d}\) for \(d \geq 2\). In this section, we will show that
where \(J_{d}\) is the minimal \(J\) such that all linear finite element functions in \(\mathbb{R}^{d}\) can be recovered by DNN \(_{J}\)
In particular, we will show the following theorem.
Theorem 8
If \(\Omega \subset \mathbb{R}^{d}\) is either a bounded domain or \(\Omega=\mathbb{R}^{d}, \mathrm{DNN}_{1}\) can not be used to recover all linear finite element functions on \(\Omega\).
Proof. We prove it by contradiction. Let us assume that for any continuous piecewise linear function \(f: \Omega \rightarrow \mathbb{R}\), we can find finite \(N \in \mathbb{N}, w_{i} \in \mathbb{R}^{1, d}\) as row vector and \(\alpha_{i}, b_{i}, \beta \in \mathbb{R}\) such that
with \(f_{i}=\alpha_{i} \operatorname{ReLU}\left(w_{i} x+b_{i}\right), \alpha_{i} \neq 0\) and \(w_{i} \neq 0 .\) Consider the finite element functions, if this one hidden layer ReLU DNN can recover any basis function of FEM, then it can recover the finite element space. Thus let us assume \(f\) is a locally supported basis function for FEM. Furthermore, if \(\Omega\) is a bounded domain, we assume that
with
as the distance of two closed sets.
A more important observation is that \(\nabla f: \Omega \rightarrow \mathbb{R}^{d}\) is a piecewise constant vector function. The key point is to consider the discontinuous points for \(g:=\nabla f=\) \(\sum_{i=1}^{N} \nabla f_{i} .\)
For more general case, we can define the set of discontinuous points of a function by
Because of the property that
we have
Note that
for \(i=1: N\) with \(H\) be the Heaviside function defined as:
This means that
is a \(d-1\) dimensional affine space in \(\mathbb{R}^{d}\)
Without loss of generality, we can assume that
When the other case occurs, i.e. \(D_{g_{6}}=D_{g_{2}}=\cdots=D_{g_{\ell_{2}}}\), by the definition of \(g_{i}\) in (33) and \(D_{g_{i}}\) in (34), this happens if and only if there is a row vector \((w, b)\) such that
with some \(c_{\ell_{i}} \neq 0\) for \(i=1: k\). We combine those \(g_{\ell_{i}}\) as
Thus, if
\(\tilde{g}_{\ell}\) is a constant vector function, that is to say \(D_{\sum_{i=1}^{k} g_{\ell_{i}}}=D_{\tilde{g}_{\ell}}=\emptyset .\) Otherwise, \(\tilde{g}_{\ell}\) is a piecewise constant vector function with the property that
This means that we can use condition (35) as an equivalence relation and split \(\left\{g_{i}\right\}_{i=1}^{N}\) into some groups, and we can combine those \(g_{\ell_{i}}\) in each group as what we do above. After that, we have
with \(D_{\tilde{g}_{s}} \neq D_{\bar{g}_{t}}\). Finally, we can have that \(D_{\tilde{g}_{s}} \cap D_{\bar{g}_{t}}\) is an empty set or a \(d-2\) dimensional affine space in \(\mathbb{R}^{d} .\) Since \(N \leq N\) is a finite number,
is an unbounded set.
If \(\Omega=\mathbb{R}^{d}\),
is contradictory to the assumption that \(f\) is locally supported.
If \(\Omega\) is a bounded domain,
Note again that all \(D_{\tilde{g}_{i}}\) ’s are \(d-1\) dimensional affine spaces, while \(D_{\tilde{g}_{i}} \cap D_{\tilde{g}_{j}}\) is either an empty set or a d-2 dimensional affine space. If \(d(D, \partial \Omega)>0\), this implies that \(\nabla f\) is continuous in \(\Omega\), which contradicts the assumption that \(f\) is a basis function in FEM. If \(d(D, \partial \Omega)=0\), this contradicts the previous assumption in (32).
Hence DNN \(_{1}\) cannot recover any piecewise linear function in \(\Omega\) for \(d \geq 2 .\)
Following the proof above, we have the following theorem
Theorem 9
\(\left\{\operatorname{ReLU}\left(w_{i} x+b_{i}\right)\right\}_{i=1}^{m}\) are linearly independent if \(\left(w_{i}, b_{i}\right)\) and \(\left(w_{j}, b_{j}\right)\) are linearly independent in \(\mathbb{R}^{1 \times(d+1)}\) for any \(i \neq j .\)
Definition of neural network space¶
Primary variables \(n_{0}=d\)
\(n_{1}\) hyperplanes
\(n_{1}\)-neurons:
\(n_{2}\)-hyperplanes
Shallow neural network functions:
\({ }_{n} \mathrm{~N}\left(n_{1}, n_{2}\right)={ }_{n} \mathrm{~N}\left(\sigma ; n_{1}, n_{2}\right)=\left\{W^{2} x^{1}+b^{2}, x^{1}=\sigma\left(W^{1} x+b^{1}\right)\right.\) with \(\left.W^{\ell} \in \mathbb{R}^{n_{\ell} \times n_{\ell-1}}, b^{\ell} \in \mathbb{R}^{n_{\ell}}, \ell=1,2, n_{0}=d\right\}\)
\({ }_{n} \mathrm{~N}\left(\sigma ; n_{1}, n_{2}, \ldots, n_{L}\right)=\left\{W^{L} x^{L-1}+b^{L}, x^{\ell}=\sigma\left(W^{\ell} x^{\ell-1}+b^{\ell}\right)\right.\) with \(\left.W^{\ell} \in \mathbb{R}^{n_{\ell} \times n_{\ell-1}}, b^{\ell} \in \mathbb{R}^{n_{\ell}}, \ell=1: L, n_{0}=d, x^{0}=x\right\}\)
First, let us first define the so-called 1-hidden layer (shallow) neural network.
The 1 -hidden layer (shallow) neural network is defined as:
The 2-hidden layer (shallow) neural network is defined as: