Convex functions and convergence of gradient descen¶
--> -->Please access the video via one of the following two ways
Convex functions and convergence of gradient descent¶
Convex function¶
Then, let us first give the definition of convex sets.
Definition 1 (Convex set)
A set \(C\) is convex, if the line segment between any two points in \(C\) lies in \(C\), i.e., if any \(x, y \in C\) and any \(\alpha\) with \(0 \leq \alpha \leq 1\), there holds
Here are two diagrams for this definition about convex and non-convex sets.
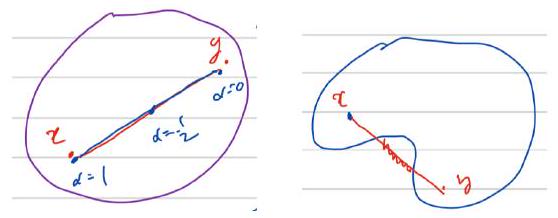
Following the definition of convex set, we define convex function as following.
Definition 2 (Convex function)
Let \(C \subset \mathbb{R}^{n}\) be a convex set and \(f: C \rightarrow \mathbb{R}\) :
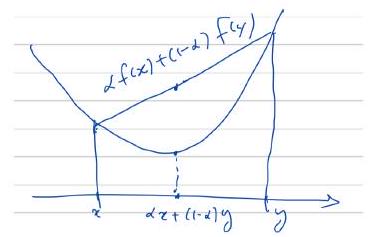
\(f\) is called convex if for any \(x, y \in C\) and \(\alpha \in[0,1]\)
\(f\) is called strictly convex if for any \(x \neq y \in C\) and \(\alpha \in(0,1)\) :
A function \(f\) is said to be (strictly) concave if \(-f\) is (strictly) convex.
We also have the next diagram for convex function definition.
Lemma 6
If \(f(x)\) is differentiable on \(\mathbb{R}^{n}\), then \(f(x)\) is convex if and only if
Based on the lemma, we can first have the next new diagram for convex functions.
.jpg)
Proof. Let \(z=\alpha x+(1-\alpha) y, 0 \leq \alpha \leq 1, \forall x, y \in \mathbb{R}^{n}\), we have these next two Taylor expansion:
Then we have
Thus we have
This finishes the proof.
On the other hand: if \(f(x)\) is differentiable on \(\mathbb{R}^{n}\), then \(f(x) \geq f(y)+\) \(\nabla f(y) \cdot(x-y), \forall x, y \in \mathbb{R}^{n}\) if \(f(x)\) is convex.
Definition 3 (\(\lambda\)-strongly convex)
We say that \(f(x)\) is \(\lambda\)-strongly convex if
for some \(\lambda>0\).
Example. Consider \(f(x)=\|x\|^{2}\), then we have
So, we have
Thus, \(f(x)=\|x\|^{2}\) is 2-strongly convex
Example. Actually, the loss function of the logistic regression model
is convex as a function of \(\theta\).
Furthermore, the loss function of the regularized logistic regression model
is \(\lambda^{\prime}\)-strongly convex \(\left(\lambda^{\prime}\right.\) is related to \(\left.\lambda\right)\) as a function of \(\theta\).
We also have these following interesting properties of convex function.
Properties (basic properties of convex function)
1- If \(f(x), g(x)\) are both convex, then \(\alpha f(x)+\beta g(x)\) is also convex, if \(\alpha, \beta \geq 0\)
2- Linear function is both convex and concave. Here, \(f(x)\) is concave if and only if \(-f(x)\) is convex
3- If \(f(x)\) is a convex convex function on \(\mathbb{R}^{n}\), then \(g(y)=f(A y+b)\) is a convex function on \(\mathbb{R}^{m}\). Here \(A \in \mathbb{R}^{m \times n}\) and \(b \in \mathbb{R}^{m}\).
4- If \(g(x)\) is a convex function on \(\mathbb{R}^{n}\), and the function \(f(u)\) is convex function on \(\mathbb{R}\) and non-decreasing, then the composite function \(f \circ g(x)=f(g(x))\) is convex.
On the Convergence of GD¶
For the next optimization problem
We assume that \(f(x)\) is convex. Then we say that \(x^{*}\) is a minimizer if \(f\left(x^{*}\right)=\) \(\min _{x \in \mathbb{R}^{n}} f(x) .\)
Let recall that, for minimizer \(x^{*}\) we have
Then we have the next tw properties of minimizer for convex functions:
If \(f(x) \geq c_{0}\), for some \(c_{0} \in \mathbb{R}\), then we have
If \(f(x)\) is \(\lambda\)-strongly convex, then \(f(x)\) has a unique minimizer, namely, there exists a unique \(x^{*} \in \mathbb{R}^{n}\) such that
To investigate the convergence of gradient descent method, let recall the gradient descent method:
Algorithm 3
For \(t = 1,2,\cdots\)
EndFor
where \(\eta_t\) is the stepsize / learning rate
Assumption
We make the following assumptions
1- \(f(x)\) is \(\lambda\)-strongly convex for some \(\lambda>0\). Recall the definition, we have
then note \(x^{*}=\arg \min f(x)\). Then we have
Take \(y=x^{*}\), this leads to
Take \(x=x^{*}\), this leads to
which means that
2- \(\nabla f\) is Lipschitz for some \(L>0\), i.e.,
Thus, we have the next theorem about the convergence of gradient descent method.
Theorem 1
For Algorithm 3, if \(f(x)\) is \(\lambda\)-strongly convex and \(\nabla f\) is Lipschitz for some \(L>0\), then
if \(0<\eta_{t} \leq \eta_{0}=\frac{\lambda}{2 L^{2}}\) and \(\alpha=1-\frac{\lambda^{2}}{4 L^{2}}<1.\)
Proof. If we minus any \(x \in \mathbb{R}^{n}\), we can only get:
If we take \(L^{2}\) norm for both side, we get:
So we have the following inequality and take \(x=x^{*}\) :
\(\left\|x_{t+1}-x^{*}\right\|^{2}=\left\|x_{t}-\eta_{t} \nabla f\left(x_{t}\right)-x^{*}\right\|^{2}\)
\(=\left\|x_{t}-x^{*}\right\|^{2}-2 \eta_{t} \nabla f\left(x_{t}\right)^{\top}\left(x_{t}-x^{*}\right)+\eta_{t}^{2}\left\|\nabla f\left(x_{t}\right)-\nabla f\left(x^{*}\right)\right\|^{2}\)
\(\leq\left\|x_{t}-x^{*}\right\|^{2}-\eta_{t} \lambda\left\|x_{t}-x^{*}\right\|^{2}+\eta_{t}^{2} L^{2}\left\|x_{t}-x^{*}\right\|^{2} \quad(\lambda-\) strongly convex and Lipschitz \()\)
\(\leq\left(1-\eta_{t} \lambda+\eta_{t}^{2} L^{2}\right)\left\|x_{t}-x^{*}\right\|\).
So, if \(\eta_{t} \leq \frac{\lambda}{2 L^{2}}\), then \(\alpha=\left(1-\eta_{t} \lambda+\eta_{t}^{2} L^{2}\right) \leq 1-\frac{\lambda^{2}}{4 L^{2}}<1\), which finishes the proof.
Some issues on GD:
\(\nabla f\left(x_{t}\right)\) is very expensive to compete.
GD does not yield generalization accuracy.
The stochastic gradient descent (SGD) method which we will discuss in the next section will focus on these two issues.