Nonlinear models¶
-->Please access the video via one of the following two ways
Nonlinear classifiable sets¶
In the section, we will extend the linearly separable sets to nonlinear case. A natural extension is like what kernel method does in SVM for binary case, we will introduce the so-called feature mapping.
Thus, we have the following natural extension for linearly separable by using feature mapping and original definition of linearly separable.
Definition 4 (nonlinearly separable sets)
These data sets
are called nonlinearly separable, if there exist a feature space \(\mathbb{R}^{\tilde{d}}\)
and a smooth (if it has derivatives of all orders) feature mapping
such that
are linearly separable.
Remark
1- This definition is also consistent with the definition of linearly separable as we can just take \(\tilde{d}=d\) and \(\varphi= id\) if \(A_{1}, A_{2}, \cdots, A_{k}\)
are already linearly separable.
2- The kernel method in SVM is mainly based on this idea for binary case \((\mathrm{k}=2)\) where they use kernel functions to approximate this \(\varphi(x)\)
3- For most commonly used deep learning models, they are all associated with a softmax mapping which means that we can interpret these deep learning models as the approximation for feature mapping \(\varphi\)
However, softmax is not so crucial for this definition actually as we have the next equivalent result.
Theorem 3
\(A_{1}, A_{2}, \cdots, A_{k} \subset \mathbb{R}^{d}\) are nonlinearly separable is equivalent that there there exist a smooth classification function
such that for all \(i=1: k\)
and \(j \neq i\)
Proof. On the one hand, it is easy to see that if \(A_{1}, A_{2}, \cdots, A_{k} \subset \mathbb{R}^{d}\)
are nonlinearly separable then they we can just take
where the \(\boldsymbol{p}(y ; \theta)\)
is the softmax function for linearly separable sets \(\varphi\left(A_{i}\right)\) for \(i = 1,2, \cdots, k\)
On the other hand, let assume that \(\psi\)
is the smooth classification functions for \(A_{1}, A_{2}, \cdots, A_{k} \subset \mathbb{R}^{d} \)
We claim that, we can take \(\varphi(x)=\psi(x)\)
and then
will be linearly separable. Actually, if you take \(\theta=(I, 0)\)
in softmax mapping \(\boldsymbol{p}(x ; \theta)\) , then the monotonicity of \(e^{x}\)
show that for all \(i=1: k \) and \(j \neq i \)
Similarly to linearly separable sets, we have the next lemme for \(k=2\)
Lemma 7
\(A _{1}\) and \(A_{2}\) are nonlinearly separable is equivalent that there exists a function \( \varphi: \mathbb{R}^{d} \mapsto \mathbb{R} \) such that
Proof. Based the equivalence of nonlinearly separable sets, there exists \(\psi_{1}(x)\) and \(\psi_{2}(2)\)
such that for all \(i=1: 2\) and \(j \neq i \)
Then, we can just take
On the other hand, if there exist \(\varphi(x)\), then we can construct \(\psi_{1}(x)\) and \(\psi_{2}(2)\) as
Remark
Here we mention that, we only assume that for all \(i=1: k\) and \(j \neq i\) we have \(\psi_{i}(x)>\psi_{j}(x), \forall x \in A_{i}\) for nonlinearly separable. We do not assume that \(\psi_{i}(x) \geq 0\) or \(\sum_{i=1}^{k} \psi_{i}(x)=1\) , which means that
is not a discrete probability distribution over all k classes.
The previous theorem shows that softmax function is not so crucial in nonlinearly separable case. Combined with deep learning models, we have the following understanding about what deep learning models are approximating.
If a classification model is followed with a softmax, then the it is approximating the feature mapping \(\varphi: \mathbb{R}^{d} \mapsto \mathbb{R}^{\bar{d}}\)
If the classification model dose not followed by softmax, then it is approximating \(\psi: \mathbb{R}^{d} \mapsto \mathbb{R}^{k}\) directly.
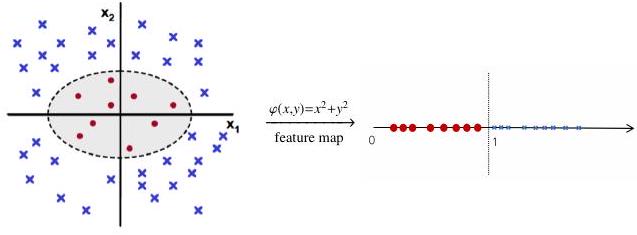
Example. Consider \(k=2\) and \(A_{1} \subset\left\{(x, y) \mid x^{2}+y^{2}<1\right\}, \quad A_{2} \subset\left\{(x, y) \mid x^{2}+y^{2}>1\right\}\), then we can have the following nonlinear feature mapping:
Here we have the following comparison for linear and nonlinear models from the viewpoint of loss functions:
Linear case (Logistic regression):
Nonlinear case:
We have the following remarks:
Remark
\(\ell(q, p)=\sum_{i=1}^{k}-q_{i} \log p_{i} \leftrightarrow \text { cross-entropy }\)
\(p(x ; \theta)=\operatorname{softmax}(W x+b)\) where \(\theta=(W, b)\)
\(\theta=\left(\theta_{1}, \theta_{2}\right)\) for nonlinear case
\(\lambda R(\|\theta\|) \leftrightarrow\) regularization term
In general, we have the following popular nonlinear models for \(\varphi(x ; \theta)\)
Polynomials.
Piecewise polynomials (finite element method).
Kernel functions in SVM.
Deep neural networks.